classSolution(object): defreverseKGroup(self, head, k): ifnot head ornot head.next: return head
cur = head cnt = 0 while cur and cnt < k: cur = cur.next cnt += 1
# case 1 : less than k nodes if cnt < k: return head
# case 2 : reverse the k nodes prev = self.reverseKGroup(cur, k) cur = head for _ in xrange(k): nxt = cur.next cur.next = prev prev = cur cur = nxt return prev
classSolution(object): defcanCross(self, stones): n = len(stones) dp = [set() for _ in range(n)] dp[0].add(1)
for i in range(1, n): for j in range(i): gap = stones[i] - stones[j] if gap in dp[j]: dp[i].add(gap - 1) dp[i].add(gap) dp[i].add(gap + 1) return len(dp[-1]) != 0
Prefix Sum
Given Array A[1..n],Prefix Sum Array PrefixSum[1..n] defined as: PrefixSum[i] = A[0]+A[1]+…+A[i-1];
Given an immutable array, call rangeSum multiple times!
1 2 3 4 5 6 7 8 9 10 11 12
classNumArray(object): # Time : O(n), Space : O(n) def__init__(self, nums): self.preSum = [0] n = len(nums) s = 0 for i in xrange(n): s += nums[i] self.preSum.append(s) # Time : O(1) defsumRange(self, i, j): return self.preSum[j+1] - self.preSum[i]
We use preSum trick in the array! How about the matrix?
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18
classNumMatrix(object): # Time : O(mn), Space : O(mn) def__init__(self, matrix): ifnot matrix: self.dp = [] return m, n = len(matrix), len(matrix[0]) self.dp = [[0] * (n+1) for _ in xrange(m+1)] dp = self.dp for i in xrange(1, m+1): for j in xrange(1, n+1): dp[i][j] = dp[i-1][j] + dp[i][j-1] - dp[i-1][j-1] + matrix[i-1][j-1]
classSolution(object):# TLE defmaxSumSubmatrix(self, matrix, k): ifnot matrix: return0 m, n = len(matrix), len(matrix[0])
# PreSum matrix dp = [[0] * (n+1) for _ in xrange(m+1)] for i in xrange(1, m+1): for j in xrange(1, n+1): dp[i][j] = dp[i-1][j] + dp[i][j-1] - dp[i-1][j-1] + matrix[i-1][j-1]
res = -float('inf') for i in xrange(m): for j in xrange(n): for li in xrange(i, m): for lj in xrange(j, n): s = sumRegion(i, j, li, lj) if s <= k: res = max(res, s) return res
Brute Force : $n^2$ subarray,Sum O($n$), Total O($n^3$)
Sol1. preSum
Improve Sum O($n^2$) to O(n),but still O($n^2$), TLE
Sol2. HashTable, O(n)
A[0] + A[1] + … + A[j] = V
preSum[j] - preSum[i] = V similar to the Two Sum Problem,Query wether another part in preSum Array?
1 2 3 4 5 6 7 8 9 10 11
classSolution(object): defsubarraySum(self, nums, k): preSum = defaultdict(int) s = count = 0 preSum[0] = 1 for n in nums: s += n if (s - k) in preSum: count += preSum[s - k] sums[s] += 1 return count
# Time : O(n), Space : O(n) # Post Order classSolution(object): defmaxDepth(self, root): ifnot root: return0 left = self.maxDepth(root.left) right = self.maxDepth(root.right) return max(left,right) + 1
A binary tree in which the depth of the two subtrees of every node never differ by more than 1.
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15
# Time : O(nlogn), Space : O(n) classSolution(object): defheight(self, root): ifnot root: return0 return max(self.height(root.left), self.height(root.right)) + 1
defisBalanced(self, root): ifnot root: returnTrue left = self.height(root.left) right = self.height(root.right) if abs(left-right) > 1: returnFalse return self.isBalanced(root.left) and self.isBalanced(root.right)
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17
# Time : O(n), Space : O(n) classSolution(object): defisBalanced(self, root): return self.dfs(root) != -1
defdfs(self, root): ifnot root: return0 left = self.dfs(root.left) if left == -1: return-1
right = self.dfs(root.right) if right == -1: return-1
DummyNode, Why or When should we use a dummy Node?
When we want to append new elements to an initially empty linkedlist, we do not have an initial head node. In this case, we can new a dummy node to act as a head node.
链表的结构发生变化
Two or More Pointers
We usually use many pointer to manipulate the node of the linked list
Basic Function
Find the middle node of a linked List
Odd, Even
1 2 3 4 5 6 7
deffindMiddleNode(head): ifnot head: return head fast = slow = head while fast.next and fast.next.next: fast = fast.next.next slow = slow.next return fast
classSolution(object): defremoveElements(self, head, val): dummyNode = ListNode(0) dummyNode.next = head prev, cur = dummyNode, head while cur: if cur.val == val: prev.next = cur.next else: prev = cur cur = cur.next return dummyNode.next
classSolution(object): defremoveNthFromEnd(self, head, n): dummyNode = ListNode(0) dummyNode.next = head slow = fast = dummyNode for _ in xrange(n): fast = fast.next
while fast.next: fast = fast.next slow = slow.next slow.next = slow.next.next return dummyNode.next
classSolution(object): defdeleteDuplicates(self, head): dummyNode = ListNode(-1) dummyNode.next = head prev = dummyNode cur = head while cur: if cur.next and cur.val == cur.next.val: while cur.next and cur.val == cur.next.val: cur = cur.next prev.next = cur.next else: prev = cur cur = cur.next return dummyNode.next
# Time : O(nlogk), Space : (k) classSolution(object): defmergeKLists(self, lists): heap = [] for head in lists: if head: heapq.heappush(heap, (head.val, head))
DummyNode = ListNode(-1) cur = DummyNode while heap: val, node = heapq.heappop(heap) if node.next: heapq.heappush(heap, (node.next.val, node.next)) cur.next = node cur = cur.next return DummyNode.next
# Step1. copy New Node cur = head nodeMap = {} while cur: nodeMap[cur] = RandomListNode(cur.label) cur = cur.next
# Step2. link the next and random pointer cur = head while cur: node = nodeMap[cur] node.next = nodeMap[cur.next] if cur.next elseNone node.random = nodeMap[cur.random] if cur.random elseNone cur = cur.next
classSolution(object): defflatten(self, head): ifnot head: returnNone stack = [] cur = head while cur: if cur.child: if cur.next: stack.append(cur.next) cur.next = cur.child cur.child.prev = cur cur.child = None
ifnot cur.next and stack: temp = stack.pop() cur.next = temp temp.prev = cur
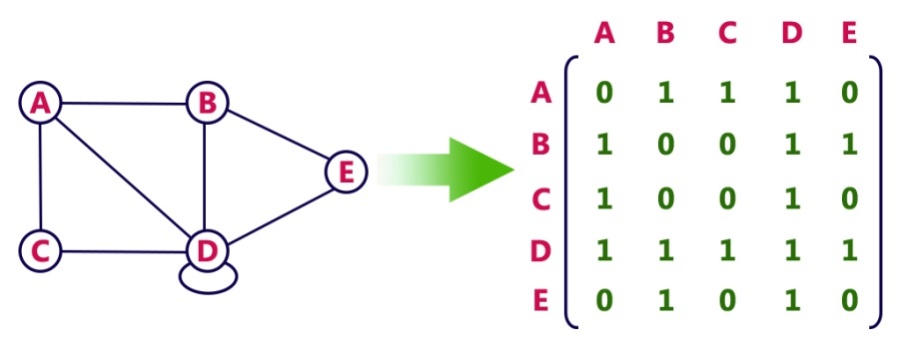
Pros: Representation is easy to implement. Edge removal takes O(1) time. Queries like whether there is an edge from vertex ‘u’ to vertec ‘v’ are efficient and can be done O(1)
Cons: Consumes more space O(V^2)(V is the number of vertex/node) Even if the graph is sparse(contains less number of edges) == waste of space
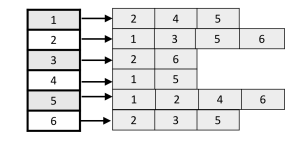
Adjacency List
Vertices/Nodes : V, Edges : E
Pros: Space Complexity = O(V + E). Adding a vertex.node to the graph is easier
Cons: Time Complexity is O(V) to check wheter there is an edge from a node to the other.(Comprared to O(1) in adjacent matrix)
# 其实和Tree的BFS traversal是一样的! # Why visited array? 如果有环的话需要,没有环的话就是tree了,所以不需要! defBFS1(): visited = [0] * n queue = collections.deque([0]) while queue: node = queue.popleft() print(node) visited[node] = 1 for nei in graph[node]: if visited[nei] == 0: queue.append(nei)
Directed Graph
Only directed graph has indegree and outdegree!
1 2 3 4 5 6 7 8 9 10
# 从Indegree == 0 的node开始! defBFS2(): queue = collections.deque([i for i in xrange(n) if indegree[i] == 0]) while queue: node = queue.popleft() print(node) for nei in graph[course]: indegree[nei] -= 1 if indegree[nei] == 0: queue.append(nei)
Dijkstra’s Algorithm
“呆克斯戳” Best First Search, 也是BFS
Usages: Find the shortest path cost from a single node (source node) to any other nodes in that graph
Data Structure: Priority Queue (Min Heap)
Process
Initial state (start node)
Node expansion/ Generation rule
Termination condition 所有点计算完毕也是”Queue is empty”
Properties
One node can be expanded once and only once
One node can be generated more than once. (cost can be reduced over time)
all the cost of the nodes that are expanded are monotonically non-decreasing(所有从 priority queue里面pop出来的元素的值是单调非递减->单调递增)
time complexity, for a graph with n node and the connectivity of the node is O(nlogn)
when a node is popped out for expansion, its value is fixed which is equal to the shortest distance from the start node (非负权重)
classSolution(object): defnetworkDelayTime(self, times, N, K): graph = [[] for _ in xrange(N+1)] for u, v, w in times: graph[u].append((v, w))
dis = [0] + [-1] * N pq = [(0, K)]
while pq: w, s = heapq.heappop(pq) if dis[s] >= 0: continue dis[s] = w for nxt, nw in graph[s]: heapq.heappush(pq, (w+nw, nxt)) return-1if-1in dis else max(dis)
classSolution(object): defisBipartite(self, graph): n = len(graph) visited = [False] * n A, B = set(), set() for i in range(n): if visited[i]: continue
queue = collections.deque([(i,0)]) while queue: node, level = queue.popleft()
if level: B.add(node) else: A.add(node)
if visited[node]: continue
for nei in graph[node]: queue.append((nei, 1 - level)) visited[node] = True returnnot A&B
gmap = {node:UndirectedGraphNode(node.label)} queue = collections.deque([node]) while queue: nnode = queue.popleft() for nei in nnode.neighbors: if nei notin gmap: gmap[nei] = UndirectedGraphNode(nei.label) queue.append(nei) gmap[nnode].neighbors.append(gmap[nei]) return gmap[node]
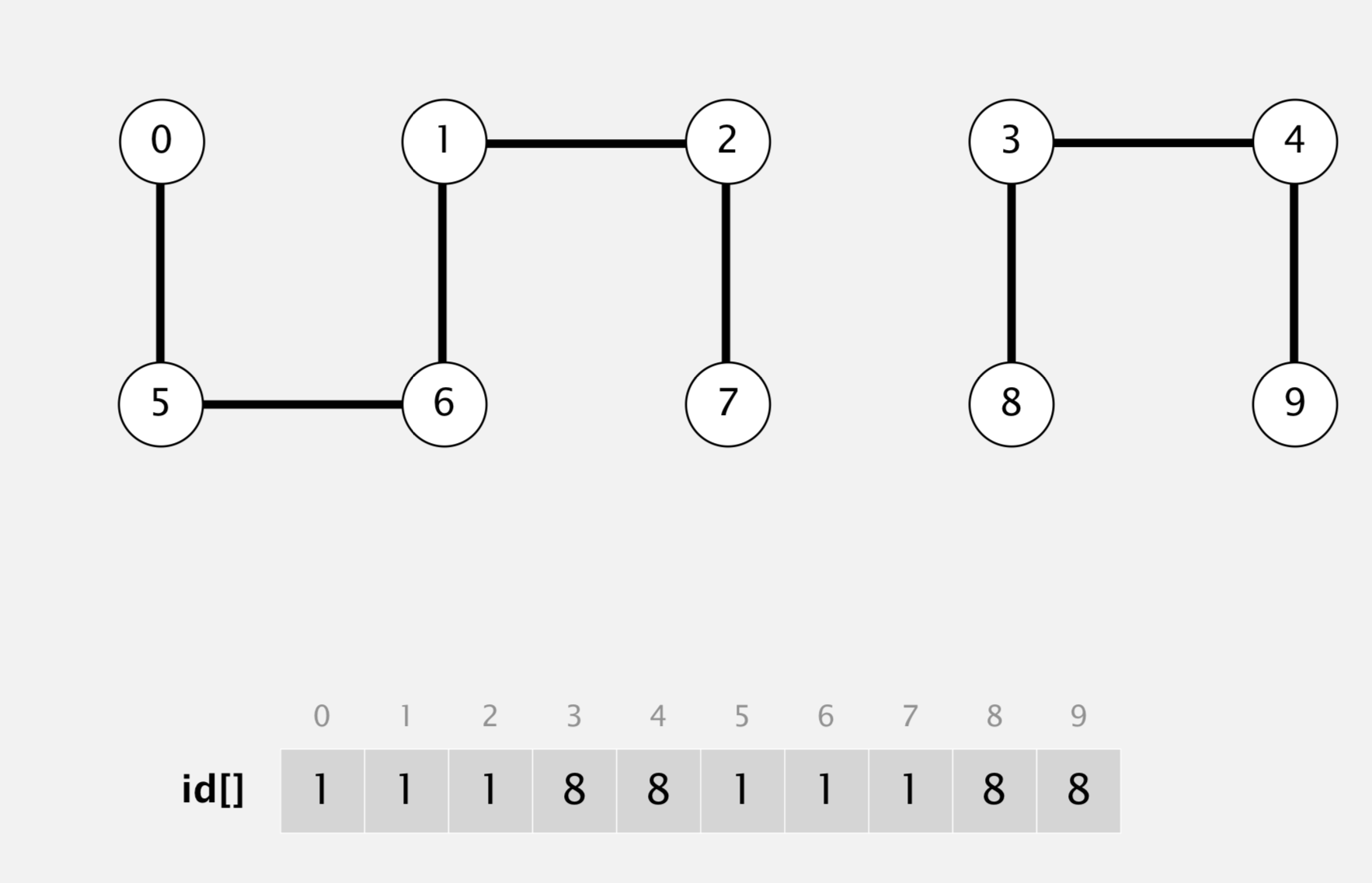
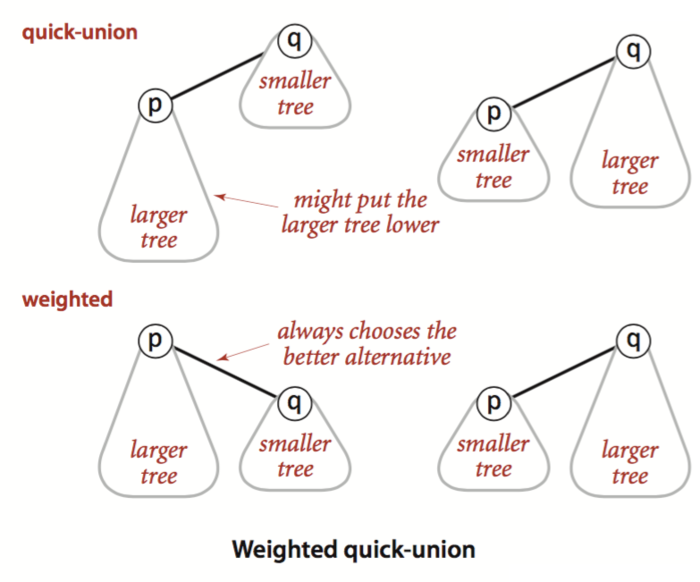
# Time : O(n) defunion(x, y): rootx = root[x] rooty = root[y] if rootx == rooty: return for i in xrange(len(root)): if root[i] == rootx: root[i] = rooty
classSolution(object): defsolve(self, board): ifnot board: return m, n = len(board), len(board[0]) total = m*n uf = UnionFind(total+1) grid = board for i in xrange(m): for j in xrange(n): if grid[i][j] == 'X': continue # Connect to "total" root if i == 0or j == 0or i == m-1or j == n-1: uf.union(total, i*n+j) else: d = [(1, 0), (0, 1), (-1, 0), (0, -1)] for k in xrange(4): ni, nj = i + d[k][0], j + d[k][1] if grid[ni][nj] == 'O': uf.union(ni*n + nj, i*n + j) for i in xrange(m): for j in xrange(n): if grid[i][j] == 'X': continue if uf.find(i*n + j) != total: grid[i][j] = 'X'
classSolution(object): defareSentencesSimilarTwo(self, words1, words2, pairs): m, n = len(words1), len(words2) if m != n: returnFalse
# 建立words到index的映射关系!UnionFind 只支持数字的index! uf = UnionFind(len(pairs)*2) cnt = 0 pdic = {} for w1, w2 in pairs: if w1 notin pdic: pdic[w1] = cnt cnt += 1 if w2 notin pdic: pdic[w2] = cnt cnt += 1 uf.union(pdic[w1], pdic[w2])
for w1, w2 in zip(words1, words2): if w1 == w2: continue if w1 notin pdic or w2 notin pdic: returnFalse if uf.find(pdic[w1]) != uf.find(pdic[w2]): returnFalse returnTrue
classSolution(object): defcountComponents(self, n, edges): visited = [0] * n graph = [set() for _ in xrange(n)] # Adjacent Table for i, j in edges: graph[i].add(j) graph[j].add(i) res = 0 for i in xrange(n): if visited[i] == 1: continue self.dfs(i, visited, graph) res += 1 return res
defdfs(self, n, visited, graph): if visited[n] == 1: return visited[n] = 1 for i in graph[n]: self.dfs(i, visited, graph)
classSolution(object): defnumIslands2(self, m, n, positions): uf = UnionFind(m * n) res = [] d = [(1, 0), (-1, 0), (0, 1), (0, -1)] for i, j in positions: p = i*n + j uf.add(p) for k in range(4): ni, nj = i + d[k][0], j + d[k][1] q = ni * n + nj if ( 0 <= ni <= m-1and 0 <= nj <= n-1and uf.root[q] != -1): uf.union(p, q) res.append(uf.cnt) return res
classSolution(object): deffindRedundantDirectedConnection(self, edges): n = len(edges) parent = [0] * (n+1) ans = None # Step1 : calculate indegree > 1 node for i in xrange(n): u, v = edges[i] if parent[v] == 0: parent[v] = u else: ans = [[parent[v], v], [u, v]] # !!! Delete the second Edge edges[i][1] = 0
# Step2 : Union Find detect cycle root = range(n+1) deffind(x): if root[x] == x: return x return find(root[x])
for u, v in edges: rootu = find(u) rootv = find(v) if rootu == rootv: # Detect Cycle ifnot ans: return [u, v] else: return ans[0] root[rootu] = rootv return ans[1]
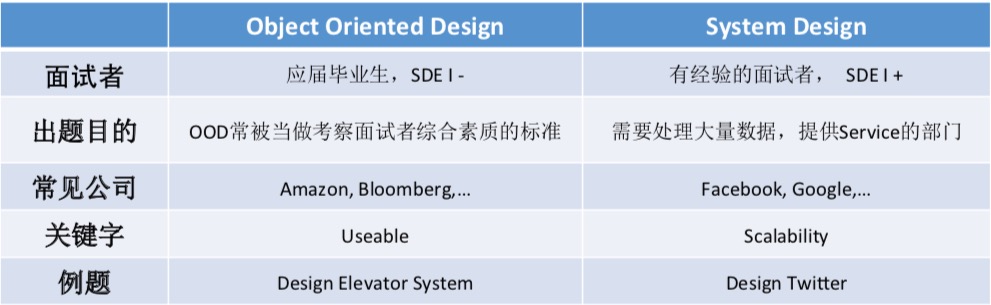
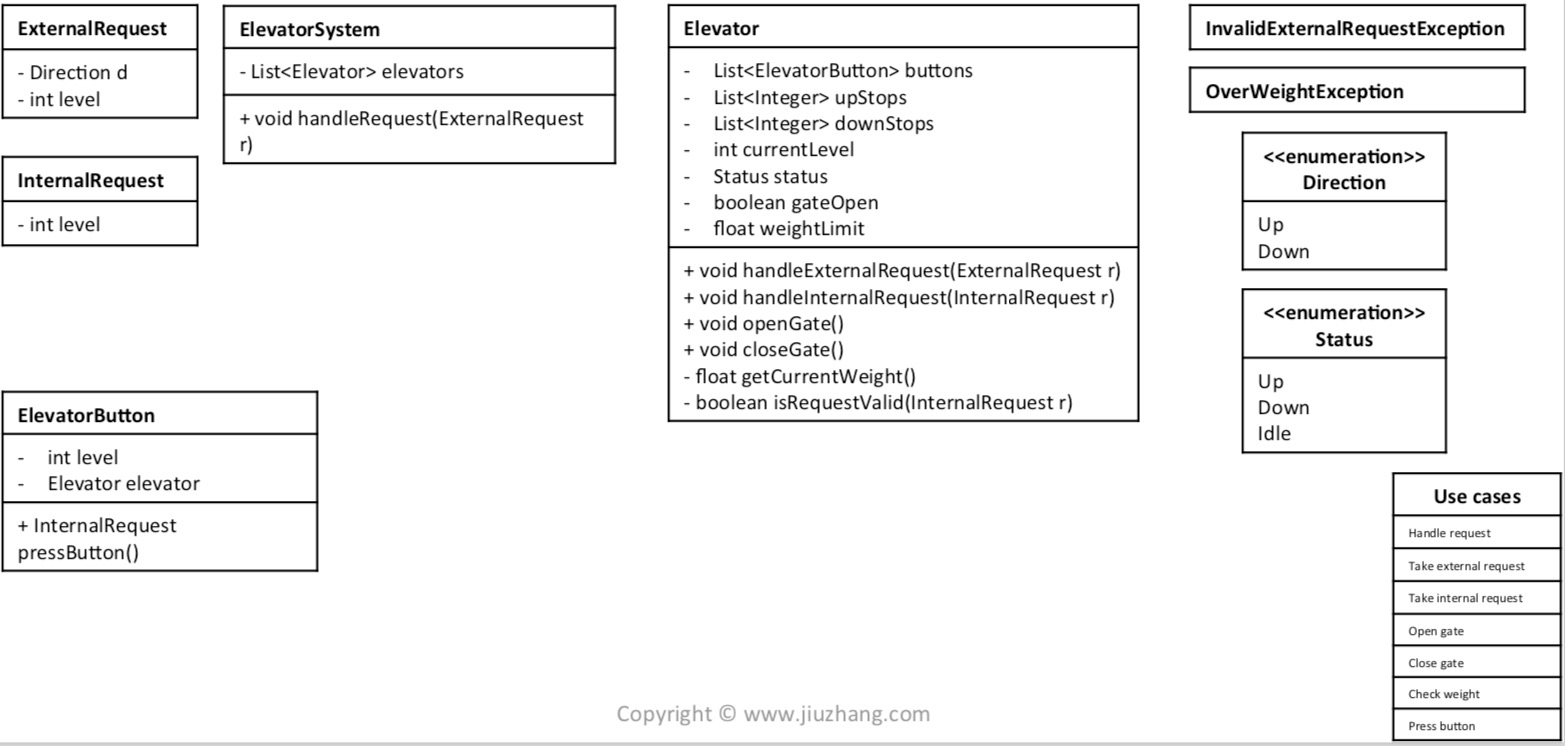
对于每一个usecase,更加详细的述这个usecase在做什么事情 (例如:take external request -> ElevatorSystem takes an external request, and decide to push this request to an appropriate elevator)
针对这个述,在已有的Coreobjects里填充进所需要的信息
Challenge
What if I want to apply different ways to handle external requests during different time of a day?
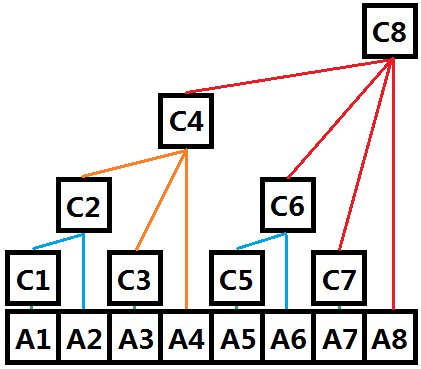
A Fenwick tree or binary indexed tree is a data structure that can efficiently update elements and calculate prefix sums in a table of numbers.
What is Binary Indexed Tree?
1 2 3 4 5
# PrefixSum defupdate(idx, n): # O(n), update idx-th num in the array defrangeSum(idx1, idx2): # O(1), calculate the sum from idx1-th to idx2-th in the arrayk
从中可以发现,若结点的标号为 n ,则该结点的求和区域长度为 2k ,此处的 k 为 n 的二进制表示的末尾 0 的个数。
1 2
# 只保留n的二进制里最低位的1 2^k = n & (n ^ (n-1)) = n & (-n)
前n项和分别保存在n二进制表示的每个“1”表示
i
二进制
包含A的个数
1
0001
1
2
0010
2
3
0011
3
4
0100
4
5
0101
1
6
0110
2
7
0111
1
8
1000
8
1 2 3 4 5 6 7 8 9 10
# Time : O(nlogn) defbuild(self, nums): n = len(nums) # BIT 数组比原数组多一位! A, C = nums, [0] * (n + 1) for i in range(n): k = i + 1# Start From i+1 while k <= n: C[k] += A[i] k += (k & -k) # Next Parent Node
defupdate(self, i, val): diff, self.A[i] = val - self.A[i], val i += 1# Start From i+1 while i <= self.n: self.C[i] += diff i += (i & -i) # Next Parent Node
defsumRange(self, i, j): res, j = 0, j + 1 while j: # 前j项和(j=j+1了,数组是从0开始index的!) res += self.C[j] j -= (j & -j) # Next Sum Node while i: # 前i-1项和 res -= self.C[i] i -= (i & -i) return res
def__init__(self, nums): self.n = n = len(nums) self.A, self.C = nums, [0] *(n + 1) for i in xrange(n): k = i + 1# tip1 : BIT index from 1 while k <= n: self.C[k] += nums[i] k += k & (-k)
defupdate(self, i, val): diff = val - self.A[i] self.A[i] = val # tip2 : remember to update original array i += 1 while i <= self.n: self.C[i] += diff i += i & (-i)
defsumRange(self, i, j): res = 0 j += 1 while j: res += self.C[j] j -= j & (-j) while i: # tip3 : excluding i, so i do not need to +1 res -= self.C[i] i -= i & (-i) return res
for row in self.preSum: for j in range(1, len(matrix[0])): row[j] += row[j-1]
defupdate(self, row, col, val): diff = val - self.matrix[row][col] self.matrix[row][col] = val
for j in range(col, len(self.matrix[0])): self.preSum[row][j] += diff
defsumRegion(self, row1, col1, row2, col2): s = 0 for i in range(row1, row2+1): row_sum = self.preSum[i][col2] - (self.preSum[i][col1-1] if col1 > 0else0) s += row_sum return s
m, n = len(matrix), len(matrix[0]) self.m, self.n = m, n self.matrix = matrix self.bit = [[0] * (n+1) for _ in xrange(m+1)] for i in xrange(m): for j in xrange(n): self.build(i, j)
defbuild(self, row, col): val = self.matrix[row][col] i = row+1 while i <= self.m: j = col + 1 while j <= self.n: self.bit[i][j] += val j += j & (-j) i += i & (-i)
defupdate(self, row, col, val): diff = val - self.matrix[row][col] self.matrix[row][col] = val i = row+1 while i <= self.m: j = col + 1 while j <= self.n: self.bit[i][j] += diff j += j & (-j) i += i & (-i)
defgetSum(self, row, col): i = row+1 res = 0 while i: j = col + 1 while j: res += self.bit[i][j] j -= j & (-j) i -= i & (-i) return res
idxes = {} for k, v in enumerate(sorted(set(nums))): idxes[v] = k + 1 iNums = [idxes[x] for x in nums] # iNums 相当于重新映射后的Array,其间数值的相对大小没有改变, # 但是值总的范围映射到了[0, n]这样就可以作为BIT的index了!!
def__init__(self, n): self.n = n self.BIT = [0] * (n+1)
defadd(self, i, val): while i <= self.n: self.BIT[i] += val i += i & -i
defsum(self, i): res = 0 while i: res += self.BIT[i] i -= i & -i return res
classSolution(object): defcountSmaller(self, nums): ifnot nums: return [] idxs = {} for k, v in enumerate(sorted(set(nums))): idxs[v] = k + 1 n = len(nums) ftree = FenwickTree(n) res = [] for i in xrange(n-1, -1, -1): res.append(ftree.sum(idxs[nums[i]]-1)) ftree.add(idxs[nums[i]], 1) return res[::-1]
queue = [root] res = [] while queue: res.append([node.val for node in queue]) nqueue = [] for node in queue: if node.left: nqueue.append(node.left) if node.right: nqueue.append(node.right) queue = nqueue return res
classSolution(object): deflevelOrderBottom(self, root): ifnot root: return [] queue = [root] res = [] while queue: res.append([node.val for node in queue]) nqueue = [] for node in queue: if node.left: nqueue.append(node.left) if node.right: nqueue.append(node.right) queue = nqueue return res[::-1]
classSolution(object): defaverageOfLevels(self, root): ifnot root: return [] res = [] queue = [root] while queue: level = [node.val for node in queue] ret = 1.0 * sum(level) / len(level) res.append(ret) nqueue = [] for node in queue: if node.left: nqueue.append(node.left) if node.right: nqueue.append(node.right) queue = nqueue return res
queue = [root] res = [] while queue: level = [node.val for node in queue] if len(res) % 2: level.reverse() res.append(level) nqueue = [] for node in queue: if node.left: nqueue.append(node.left) if node.right: nqueue.append(node.right) queue = nqueue return res
Another Solution : Use Deque! In the even level:expand a node from the right end of the dequ, generate right and then left child, and insert them to the left end of the deque.
queue = [(root, 0)] res = 1 while queue: nqueue = [] for node, idx in queue: if node.left: nqueue.append((node.left, 2*idx)) if node.right: nqueue.append((node.right, 2*idx+1)) if nqueue: res = max(res, nqueue[-1][1] - nqueue[0][1] + 1) queue = nqueue return res
In Java, STACK is usually a size limited memory area.By default, a several thousands levels recursion call would easily eat up all the space and throw StackOverFlowException - this is something you have to keep in mind
Iterative way is good because it needs much less space of STACK(There is probably only O(1) method call levels, so O(1) space on STACK.)
It is not easy to convert all recursion solutions to a “while loop” solution without any other auxiliary data structures’ help.
There are two paths of recursion need to follow instead of one, and we need to finish the first branch, then the second one.
In this case, we will need something else to help us:
The recursion is internally done by using STACK to maintain the method call levels and directions, we can simulate this ourselves, so a stack will be needed.
The difference is, we use our own stack and the space used by our own stack is on HEAP. The space consumed on STACK is trivial.
We do not change the total space consumption, but we move out the space consumption of STACK to HEAP!!!
classSolution(object): definorderTraversal(self, root): ifnot root: return [] left = self.inorderTraversal(root.left) right = self.inorderTraversal(root.right) return left + [root.val] + right
Iteration (Stack + cur)
The problem is, we can not throw away the root in the stack before we traversed all the nodes in left subtreee. How can we know we have already traversed all the nodes in left sub?
The root is the top element in the stack, use a helper node to store the next “visiting” node and subtree.
1 When helper node is not null, we should traverse the subtree, so we push helper and we go left
2 When helper is null, means the left subtree of the roots finished, the root is the top element in the stack. We can print the top, and let helper = top.right.(traverse the left subtree firtst, then top. then right subtree)
3 do 1 and 2 until helper is null and there is no nodes left in the stack
# 写法1. classSolution(object): definorderTraversal(self, root): ifnot root: return [] res, stack = [], [] cur = root while stack or cur: while cur: stack.append(cur) cur = cur.left cur = stack.pop() res.append(cur.val) cur = cur.right return res
stack, res = [], [] cur = root while stack or cur: if cur: stack.append(cur) cur = cur.left else: cur = stack.pop() res.append(cur.val) cur = cur.right return res
classSolution(object): definorderTraversal(self, root): ifnot root: return [] left = self.inorderTraversal(root.left) right = self.inorderTraversal(root.right) return left + right + [root.val]
Iteration
解法1. Two Stacks
left->right->root (reverse)=> root->right->left
Preorder -> Postorder
1 2 3 4 5 6 7 8 9 10 11
classSolution(object): defpostorderTraversal(self, root): # Pre-order, but root->right->left stack, res = [root], [] while stack: node = stack.pop() if node: res.append(node.val) stack.append(node.left) stack.append(node.right) return res[::-1]
What is the drawback of two stacks solution, if we deal with the nodes on the fly? (Online) Need to store everything in memory before we can get the whole post order traversal sequenct.
解法2. Stack + cur + prev
The problem is, we need to traverse both left and right subtrees first, then we can eliminate the root from the stack. We need an mechanism to know, when we finished visiting all subtrees’ nodes.
What we need to know?
Direction!!!!!!!
we are visiting down? or returning from left? or returning from right?
思路1. 细分三种case The root is the top element in the stack Maintain a previous Node, to record the previous visiting node on the tracersing path, so that we know what the direction we are taking now and what is the direction we are taking next.
root = stack.top
if previous is null -> going down(left subtree has priority)
if previous is current’parent -> going down (left subtree has priority)
if previous == current.left -> left subtree finished, going current.right
if previous == current.right -> right subtree finished, pop current, going up.
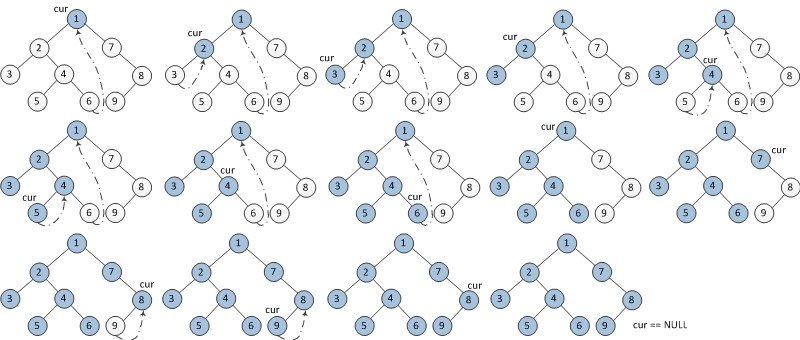
# Inorder Demo Morris Traversal classSolution(object): definorderTraversal(self, root): ifnot root: return [] res = [] cur = root while cur: ifnot cur.left: res.append(cur.val) cur = cur.right else: # 1 Find Inorder Predecessor of cur prev = cur.left while prev.right and prev.right != cur: prev = prev.right
# 2 Connect or Restore the Pointer ifnot prev.right: prev.right = cur cur = cur.left else: prev.right = None res.append(cur.val) cur = cur.right return res