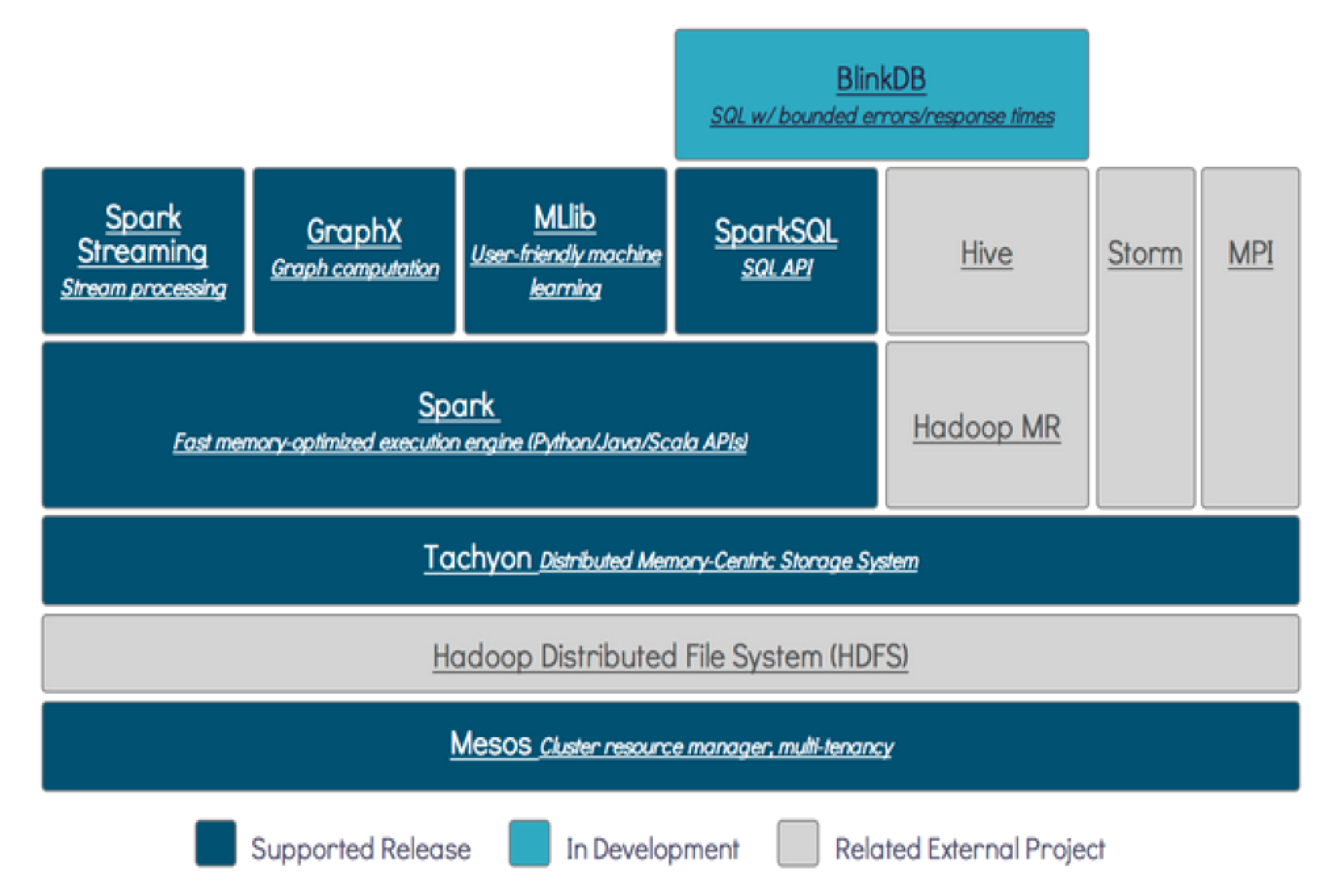
Apache Spark™ is a unified analytics engine for large-scale data processing.
- Speed
- Computation optimization (DAG, thread-based)
- In memory computing
- Easy to Use & Generality
- Interactive Shell with the Scala, Python, R, and SQL shells.
- 80 high-level operators that make it easy to build parallel apps.
- Combine SQL, streaming, and complex analytics.(多个框架的学习成本)
- Runs Everywhere
- Spark runs on Hadoop, Apache Mesos, Kubernetes, standalone, or in the cloud.
- 技术选型!Access data in HDFS, Apache Cassandra, Apache HBase, Apache Hive, and hundreds of other data sources.
Overview
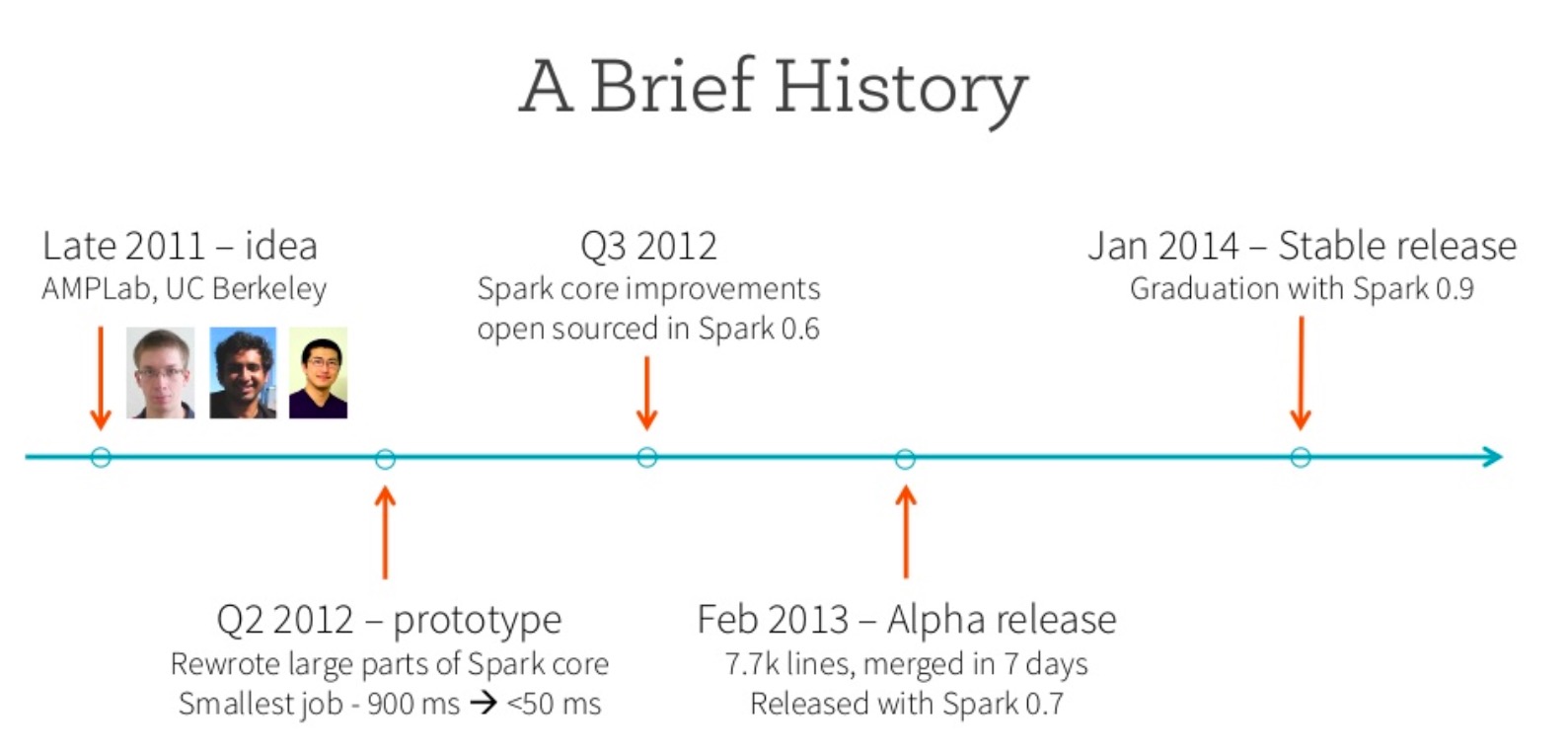
History
Quick Start Reference : Quick Start Spark
Install Spark without Hadoop
- Download a packaged release of Spark from the Spark website.
- Since we won’t be using HDFS, you can download a package for any version of Hadoop.
- 下载即可用
Interact with the Spark Shell
Spark’s shell provides a simple way to learn the API, as well as a powerful tool to analyze data interactively. It is available in either Scala or Python.
Start
- Start it by running pyspark in the Spark directory
1 | ./bin/pyspark |
DataSet
Spark’s primary abstraction is a distributed collection of items called a Dataset.(Before Spark2.x, it called Resilient Distributed Dataset (RDD)) Datasets can be created from Hadoop InputFormats (such as HDFS files) or by transforming other Datasets.
Due to Python’s dynamic nature, we don’t need the Dataset to be strongly-typed in Python. As a result, all Datasets in Python are Dataset[Row], and we call it DataFrame to be consistent with the data frame concept in Pandas and R.
- Make a new DataFrame from the text of the README file
1 | >>> textFile = spark.read.text("README.md") |
- Transform this DataFrame to a new one
1
2
3
4
5# We call filter to return a new DataFrame with a subset of the lines in the file.
>>> linesWithSpark = textFile.filter(textFile.value.contains("Spark"))
# How many lines contain "Spark"?
>>> textFile.filter(textFile.value.contains("Spark")).count()
20
Self-Contained Applications
Scala (with sbt), Java (with Maven), and Python (pip).
- This program just counts the number of lines containing ‘a’ and the number containing ‘b’ in a text file.
1 | """spark-test.py""" |
Install pySpark
1
> pip install pyspark
Run the simple application
1
2
3
4> python spark-test.py
........
Lines with a: 61, lines with b: 30
.......
Spark Streaming With Kafka
SparkContext
- Main entry point for Spark functionality.
- A SparkContext represents the connection to a Spark cluster, and can be used to create RDD and broadcast variables on that cluster.
- master = “local[2]”, appName = “StockAveragePrice“
1
2
3from pyspark import SparkContext
sc = SparkContext("local[2]", "StockAveragePrice")
sc.setLogLevel('ERROR')
StreamingContext
- Main entry point for Spark Streaming functionality.
- A StreamingContext represents the connection to a Spark cluster, and can be used to create DStream various input sources.
1
2
3from pyspark.streaming import StreamingContext
ssc = StreamingContext(sc, 5)
# sparkContext = sc, batchDuration = 5
KafkaUtils
- KafkaUtils.createDirectStream(ssc, topics, kafkaParams,…)
- Create an input stream that directly pulls messages from a Kafka Broker and specific offset.
1
2
3
4
5
6
7
8from pyspark.streaming.kafka import KafkaUtils
topic = "test"
brokers = "192.168.99.100:9092"
# Kafka Consumer
directKafkaStream = KafkaUtils.createDirectStream(
ssc,
[topic],
{'metadata.broker.list': brokers})